
Research
My research has mostly revolved around the general topic of deep reinforcement learning (RL). Currently, I am interested in investigating the adversarial robustness of reinforcement learning algorithms in order to stabilize deep RL training as well as improve generalization.
Reliable Reinforcement Learning
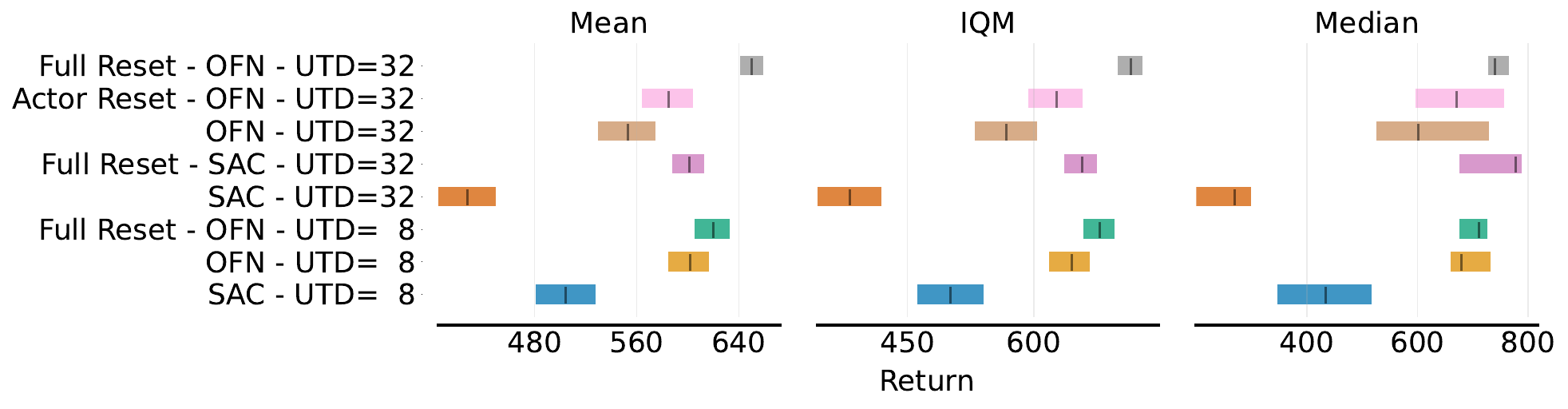
Dissecting Deep RL with High Update Ratios: Combatting Value Divergence
A fundamental question in deep reinforcement learning is that of fitting Q-value functions correctly. While in other domains, increasing the number of gradient steps on a fixed amount of data has proven to be quite effective, deep RL suffers from particular challenges. In this work, we focus on continuous control actor critic methods and demonstrate that increasing the so-called update-to-data ratio in deep RL leads to a divergence in the prediction of Q-values. While previous work argues for over-fitting in early stages due to high update ratios, we demonstrate that the opposite is happening and Q-values are not being fit at all. Then, we propose a simple normalization fix which we refer to as output feature normalization (OFN). OFN simply projects the outputs of the last hidden layer of the Q-value network onto the unit ball. As a result, we recover learning in agents with very large update ratios and in combination with other tricks provide very strong results, even on the challenging DM Control dog tasks which are usually only tackled using model-based approaches.
Replicable Reinforcement Learning
Replicability has proven to be a key concern in the field of machine learning and especially reinforcement learning. In this paper, we introduce a formal notion of Replicable Reinforcement Learning. A Replicable Reinforcement Learning algorithm produces (whp.) identical policies, value functions or MDPs across two runs of the same algorithm. In our work we provide a first set of formally replicable algorithms for sample-based value iteration and exploration. First, we assume the generative model setting with access to a parallel sampling sub-routine. In this setting, our first algorithm called Replicable Phased Value Iteration replicably produces the exact same value function across two runs. Then, we consider the episodic setting where an agent needs to explore the environment. Our Rep. Episodic R-Max finds a sequence of replicable known state-actions pairs to compute identical MDPs across different runs showing that exploration can be done replicably. We also experimentally validate our algorithms. We show they do have some sample-complexity overhead but it is not as large as theory would suggest.

Theory to Practice Reinforcement Learning
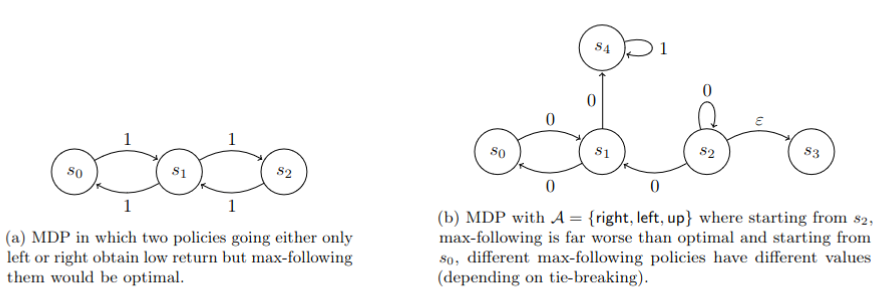
Oracle-Efficient Reinforcement Learning for Max Value Ensembles
Real-world settings in reinforcement learning often come with large state-action spaces that prove to be quite challenging. Finding solutions that have both theoretical guarantees and are practically applicable is difficult in such complex settings. One of the major challenges comes from the fact that an optimal policy must be optimal everywhere. In this work, we follow a line of work that tries to address these challenges by ensembling multiple given policies rather than learning policies from scratch. We assume access to a value function oracle on samplable distributions. We then provide sample complexity bounds for finding an approximate max-following policy which can be arbitrarily better than any of the given constitutuen policies. We also provide several intuitive MDP examples that highlight the difficulty of learning max-following policies in approximate settings. My favorite part about this paper is the idea of the value-oracle assumption. Since we only have to do on-policy estimation of this function, it is very cheap to do using neural networks. This allows us to derive a provable efficient algorithm that is still practically relevant.
Structure in Reinforcement Learning Agents
Robotic Manipulation Datasets for Offline Compositional Reinforcement Learning
A follow-up work to the earlier CompoSuite, we develop four offline reinforcement learning datasets that follow the compositional structure of CompoSuite. This allows us to create a large dataset of 256 simulated robotics tasks totalling 256 million transition datapoints. We further show that current offline RL methods cannot extract the compositional structure from the data even when using an approach that was successful in the online setting. The datasets can be accessed here https://datadryad.org/stash/dataset/doi:10.5061/dryad.9cnp5hqps.
Composuite: A Compositional Reinforcement Learning Benchmark
In my first paper as a PhD student, we created a benchmark called CompoSuite to analyze the compositionality of RL algorithms. CompoSuite consists of 256 distinct tasks that are designed compositionally. Each task requires the agent to use a robot arm to manipulate an object and achieve an objective while avoiding an obstacle. To enable RL training, each task comes with shaped reward functions. In CompoSuite, reasoning via composition should enable an agent to transfer knowledge across tasks. We show that a compositional learner is able to learn all possible tasks and can zero-shot transfer to unseen tasks while a classical multi-task learner has trouble generalizing.

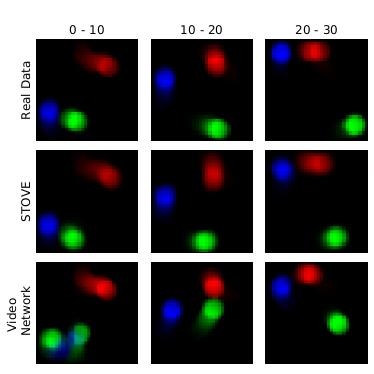
Structured Object-Aware State Representation Learning
For my Master’s thesis, I worked on object-aware state representations for deep (RL). We used a dynamics prediction model to extract concrete positions and velocities from visual observations. Positions and velocities are encoded in a structured latent space and used for world-model prediction. We showed how these structured representations can be used for planning and model-based RL and how they can speed up model-free reinforcement learning training. Part of the work conducted during the thesis was then published in our work on Structured Object-Aware Physics Prediction for Video Modeling and Planning at ICLR 2020.
Deep and Hierarchical Reinforcement Learning
Learning to play StarCraft II
During my Master’s degree, I first got in contact with the subject of RL in a research project at Jan Peter’s lab. We created an open-source repository to reproduce the results of the first paper learning to play parts of the real-time strategy video game StarCraft II (SC2). The code and report are available here. In a separate strain of follow-up work, we extended the implementation to include the then-new Proximal Policy Optimization algorithm which had not been tested on SC2. Additionally, we extended the Feudal Networks neural network architecture with spatially aware actions in the hopes of learning priors that can help transfer policy across games. The code with the extended content as well as the report can be found here.
Here is a video of the original A3C agent trained using our implementation ![]() .
.
Non-RL Work
Distributed Continual Learning
In this work, we establish a framework at the intersection of continual and distributed learning. We provide a mathematical formulation generalization several previous works, and develop several novel algorithms to handle the various challenges emerging in this setting. This includes statistical heterogeneity, continual distribution shift, network topologies, and communication constraints. We demonstrate that sharing parameters is more efficient than sharing data as tasks become more complex; modular parameter sharing yields the best performance while minimizing communication costs; and combining sharing modes can cumulatively improve performance.